Get The The AI Search Optimization Checklist Worksheet
Updated on May 28, 2026
If you want to improve AI search visibility consistently, you need to go beyond isolated content tweaks and work with a clearer optimization workflow: which prompts and journeys matter, where your brand is already present or missing, which pages and sources shape the answers, what needs to be fixed, and how you will validate whether those changes actually moved the needle.
That’s what this checklist is for: It’s the execution layer of the AI search optimization process: a practical way to move from “we should optimize for AI search” to better questions, such as:
- Which AI search journeys do we want to influence?
- Where are we visible, cited, recommended or missing?
- Which owned pages and third-party sources are shaping the answers?
- What do we need to improve to be selected, cited, recommended and accurately represented?
- How will we measure progress without overclaiming impact?
This checklist is also designed to complement my other AI search guides:
- For the structural diagnosis, start with the 10 key characteristics of AI search winning brands.
- For measurement, use the 3-layer framework to measure AI Presence, Readiness and Business Impact.
- For the AI traffic vs citation implications behind Step 6, see my AI traffic vs AI citations research.
Let’s go through it.
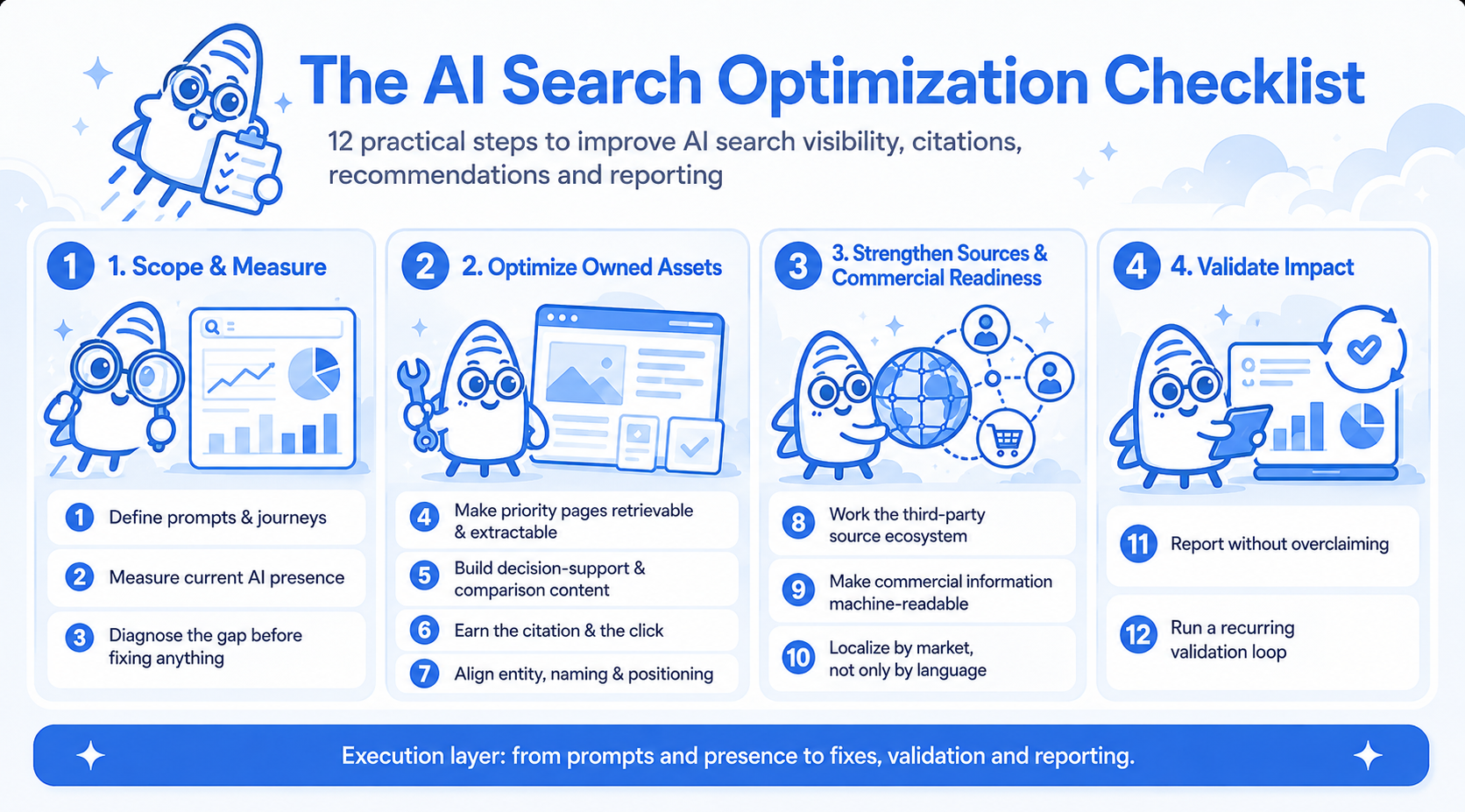
Before using this checklist, don’t start from a blank page. The workflow becomes much more useful when you bring together the inputs that show what matters to the business, how users search and decide, where the brand already has visibility, and which sources may influence AI answers.
At a minimum, gather:
- Your priority products, services, categories or markets.
- Your main competitors by product line, audience segment and market.
- Existing SEO data: top organic landing pages, relevant queries, conversions, branded vs non-branded demand, and pages that already support commercial journeys.
- Sales, support and customer language: recurring objections, comparison questions, use cases, constraints and decision criteria.
- Current AI referral traffic and top AI landing pages, if available.
- Known prompts, queries or sampled AI traffic prompts from your own analytics, AI visibility tools, Bing Webmaster Tools AI Performance data or competitive intelligence platforms.
- Third-party sources where your brand or competitors are already mentioned: review platforms, marketplaces, directories, partner pages, industry publications, forums and communities.
- Existing structured data, product feeds, local profiles, app store listings, marketplace profiles and partner listings.
- Business priorities: which journeys, products, services, markets or customer segments matter most this quarter.
The goal isn’t to audit everything with the same level of depth but to focus the checklist on the AI search journeys that matter most, and on the pages, sources and signals that are most likely to influence those journeys.
1. Define the prompts and journeys you actually want to influence
Are we optimizing for the prompts and journeys that actually matter?
The first mistake I see some still make is to start “optimizing for AI search” without defining what that means. AI search visibility isn’t one generic outcome: A brand can be visible for informational prompts, absent from commercial comparison prompts, misrepresented in evaluation prompts, and cited only through third-party sites instead of its own pages.
To avoid this issue, build a prompt library around how buyers actually decide through the full customer journey, not keywords stretched into questions. The strongest libraries come from non-brand demand data, sales and support transcripts, review and community language, and AI research tool samples, not from a keyword tool alone.
What to define
- Priority products, services or categories, and the journey stages you want to influence.
- Markets, languages, personas and the real buyer constraints: price band, company size, vertical, integrations, geography and compliance.
- The competitors users compare you against, and the AI platforms your audience actually uses.
- Prompt types across the funnel: discovery, problem solving, comparison, alternatives, evaluation, shortlist, transactional, local and constraint-led.
What good looks like
A useful prompt library is grouped by product or service, persona, funnel stage, market, language and prompt type. It includes non-branded, commercial, comparison, constraint-led and local prompts, and each prompt group has a clear priority level based on business importance.
Example
For example, for a PR opportunity discovery tool like Finchling, I would not only track “best PR tool”, I would track constrained prompts buyers are more likely to use, such as: “What are the best PR opportunity tools for a 10-person digital PR agency managing 15 B2B tech clients that needs Slack integration?” or “Finchling vs Google Alerts for a small PR agency managing multiple B2B SaaS clients?”.
What to avoid
- Tracking only head terms rewritten as questions, or treating branded prompts as the main benchmark.
- Using one global prompt set for every market, and ignoring commercial and comparison prompts because they feel uncomfortable.
- Over-indexing on branded prompts. As a rule of thumb, I keep most prompt libraries weighted heavily toward non-branded prompts, because that is where discovery and selection usually happen.
How to put it into practice
Use the Presence layer in my 3-layer framework to measure AI Presence, Readiness and Business Impact to structure the prompt groups you will track and optimize.
The goal is not to build the biggest possible prompt list, but the most representative one: prompts that reflect the products, markets, personas, use cases and decisions that matter to the business.
If you’re working across countries or languages, use my global AI search strategy guide too. It will help you avoid one of the most common mistakes: using the same prompt set, competitors and source assumptions across markets where AI search behavior can differ significantly.
2. Measure your current AI presence before changing anything
Do we appear, get recommended, cited and described accurately?
Once you have the library, measure what’s actually happening in the answers you want to influence. Optimization should start from observed presence, not from a reflex to create more content.
Use the five Presence KPIs: Track them by platform, prompt type, market, product line and journey stage and analyze at the topic level, not only the individual prompt level, since AI outputs vary by session. Because AI answers can vary across runs, treat individual prompt outputs as samples, not fixed rankings.
| Presence KPI | Question it answers | How to calculate |
|---|---|---|
| Prompt coverage | Are we showing up where we need to? | Prompts where the brand appears / total tracked prompts |
| Recommendation rate | Are we endorsed, or just mentioned? | Appearances where AI recommends the brand / appearances |
| Linked citation rate | Is the visibility click-capable? | Appearances with a clickable link / appearances where links are surfaced |
| Comparative win rate | Do we win the shortlist? | Comparison prompts preferred / comparison prompts where we appear vs competitors |
| Representation accuracy | Are we described correctly? | Appearances with correct positioning / appearances |
Method note
Recommendation rate, comparative win rate and representation accuracy are not platform ground truth. They need a documented rubric, repeated sampling and human review, so report them separately and label confidence.
What good looks like
Each priority prompt group has a documented baseline: whether the brand appears, whether it is recommended, whether it receives a linked citation, whether competitors are preferred, which sources are cited and whether the representation is accurate. Individual outputs are treated as samples, not fixed rankings.
What to avoid
- Using one platform as representative of all AI search, or running each prompt once and treating it as definitive.
- Blending AI Overviews, AI Mode, ChatGPT, Perplexity, Gemini, Claude and Copilot into one “AI visibility” score. They differ enough that blending hides the signal.
- Tracking only whether you appear, without checking recommendation, citation, accuracy or competitive preference.
How to put it into practice
Use the five Presence KPIs from my 3-layer framework to measure AI Presence, Readiness and Business Impact as your measurement baseline: prompt coverage, recommendation rate, linked citation rate, comparative win rate and representation accuracy.
This will help you avoid reducing AI visibility to a simple “mentioned / not mentioned” check. A brand can appear in an answer but not be recommended, be recommended but not linked, or be cited through third-party sources rather than its own pages. These differences matter when deciding what to fix next.
3. Diagnose the gap before you fix anything
Which readiness characteristic is actually causing the gap?
Once you know where you appear and you don’t, diagnose why. A visibility gap can come from very different causes, and the fix is completely different for each. Don’t assume every problem is a content problem.
| AI search issue | Likely readiness gap | Optimization action |
|---|---|---|
| Absent from commercial prompts | Useful / Differentiated | Create decision-support and comparison content |
| Appears but not recommended | Differentiated / Credible | Add clear fit, trade-offs, evidence and customer proof |
| Appears but not linked | Extractable / Useful | Improve answer-first structure, specificity and freshness |
| Misdescribed | Recognizable / Consistent | Fix owned descriptions, schema, profiles and listings |
| Competitors dominate locally | Corroborated locally | Strengthen local pages, listings, reviews and sources |
| Not retrievable at all | Accessible | Fix crawl, render, index and feed access |
What good looks like
Every meaningful visibility gap has a hypothesis attached to it: owned content gap, third-party source gap, entity or positioning inconsistency, technical access issue, commercial data gap, local-market issue or credibility/proof gap. The next action should be tied to that hypothesis, not to a generic best practice.
What to avoid
- Creating new pages when the real gap is third-party corroboration, or doing technical fixes when the real gap is weak positioning.
- Running a generic audit disconnected from the actual prompts, or prioritizing actions that do not map to a measurable visibility issue.
How to put it into practice
Use my 10 key characteristics of AI search winning brands as the diagnostic layer once you know where the visibility gaps are.
For example, a visibility issue may point to an accessibility problem, an extractability problem, weak differentiation, inconsistent entity signals, limited third-party corroboration, low credibility, or unclear transactional information. Mapping the gap to the right characteristic helps you avoid applying the wrong fix.
4. Make priority pages retrievable and extractable
Can systems reach, render and isolate our priority pages?
Audit this on the pages that matter most for your target prompts and don’t assume a page is AI-ready just because it ranks in traditional search:
Is your content accessible?
- Review AI crawler access. Make sure important search crawlers can access priority content, and document the visibility, training, licensing and legal trade-offs of allowing or blocking AI related crawlers such as GPTBot, Google-Extended, ClaudeBot, CCBot and PerplexityBot.
- Know what each crawler actually governs, because they don’t do the same job: Google-Extended controls whether your content can be used to help improve Gemini Apps and Vertex AI generative APIs; it doesn’t govern your eligibility for Google Search surfaces such as AI Overviews or AI Mode, which rely on Googlebot and standard Search controls.
- Critical content and internal links are server-rendered or reliably rendered HTML, not dependent on fragile client-side JavaScript; canonicals are correct; no noindex or restrictive snippet directives apply to content you want surfaced.
- For ecommerce: product pages are crawlable, feeds are complete and current, and structured data matches on-page content, including price, stock, variants and availability.
Is your content extractable?
- The heading describes the question; the first sentence answers it directly; each section covers one idea and can stand alone.
- Definitions, criteria, pros and cons, steps and comparisons are explicit; tables are used where they make comparison easier; entities are named explicitly.
What good looks like:
Priority pages are crawlable, indexable, internally linked, rendered reliably and structured so that important sections can be understood on their own. Key answers, comparisons, criteria, prices, product attributes and entity names are not hidden in fragile scripts, images or PDFs.
Example
Instead of “Our platform helps teams work better with flexible workflows,” write something extractable: “[Product] is best for small and mid-sized agencies managing client approvals, recurring workflows and multi-user collaboration in one place. It isn’t built for enterprise resource planning or complex financial forecasting.”
How to put it into practice
Use the Accessible and Extractable characteristics in my 10 key characteristics of AI search winning brands guide to audit the pages that should support your most important prompts.
Focus especially on pages that should be cited or used for commercial, comparison, local or evaluation queries. These are the pages where crawlability, renderability, clear structure, answer-first sections, descriptive headings, comparison tables and machine-readable information can directly affect whether the content is usable in AI answers.
5. Build decision-support and comparison content, not only informational coverage
Do our pages help users compare, evaluate and choose?
Purely informational content rarely gets you recommended in commercial journeys, the valuable prompts are asking for selection support: which option to choose, which provider to consider, which alternative fits a specific need. Comparative win rate is where this shows up.
Questions your pages should answer
- Who is this best for and who is it not ideal for?
- What problem does it solve, and how does it compare with alternatives?
- What are the selection criteria, the trade-offs, the cost, the proof and the next step?
Validations to make when creating new pages
AI search optimization should not create a messy content architecture or duplicate pages that compete with existing SEO assets. Before creating a new page, check whether the intent is genuinely new or whether an existing page should be expanded:
- Is there already a page ranking, converting or supporting this intent?
- Should the existing page be expanded instead of creating a new one?
- Is this prompt a new intent, or a constraint variant of an existing intent?
- Would the new page compete with an existing category, solution, comparison, use-case or pricing page?
- Would the answer work better as a section, FAQ, comparison module, table, tool, data asset or standalone page?
- Is the page likely to attract external references or citations, or is it mainly supporting conversion once users already know the brand?
- Does the internal linking structure make the relationship between the new or updated page and the existing page set clear?
The best outcome is not always “create another page”. Often, the better fix is to improve an existing page so it is more specific, extractable, decision-supportive and internally connected.
Formats that earn selection
Comparison and alternatives pages, “best for” and use-case pages, buyer guides, pricing and plan explainers, integration pages and segment-specific proof.
What good looks like
Important commercial prompts are supported by pages or sections that help users evaluate options: who the product or service is best for, when it is not a fit, how it compares with alternatives, what it costs, what proof supports it and what the next step is.
What to avoid
“Best” lists with no real criteria, comparison pages that only say you are better, and avoiding trade-offs or fit. Forcing users and AI systems to infer who the product is for is a self-inflicted visibility gap.
How to put it into practice
Use the Useful and Differentiated characteristics in my 10 key characteristics of AI search winning brands guide to review whether your content gives AI systems a clear reason to include or recommend your brand.
This is where fit, trade-offs, use cases, pricing, alternatives, limitations, comparisons and proof become especially important. If the page only explains the topic but does not help users choose, it is less likely to support recommendation and shortlist visibility.
For the citation implications of this, see my AI traffic vs AI citations research, especially where discovery and evaluation pages play a different role from the pages that receive AI referral clicks.
6. Earn the citation and the click
Are we trusted enough to be cited and useful enough to be linked?
A brand can appear in an AI answer without getting the click. My AI Traffic vs AI Citations April 2026 USA analysis of 40 sites using Semrush data makes this concrete: brand-entry pages took 57.7% of AI traffic but only 3.0% of AI citations, while citations were much more distributed across discovery and evaluation pages than clicks were.
This is why AI search optimization needs to separate two jobs: earning the citation in discovery and evaluation journeys, and earning the click when users already have enough brand familiarity or intent to visit.
Make claims citation worthy
- Claims are specific and verifiable; statistics are sourced and current; methodology is stated for research, rankings or benchmarks; authors are named, especially in YMYL or high-trust topics.
- Freshness is visible where it matters: publication and update dates, current data, and content that adds something beyond summarizing others.
Improve linked citation potential
- If your own site is rarely cited for prompts where it should be the primary source, diagnose why: are the cited sources answering more directly, more current, more neutral or comparative, easier to extract, or simply offering data and proof your page lacks?
- Improve the direct answer; add comparison tables, criteria, examples, pricing, limitations, evidence and methodology; update stale information; strengthen internal links; or build a better page for that specific prompt intent.
Create citation worthy assets that compound
Original research, surveys, benchmarks, data studies, free tools, methodology-led reports and frequently updated reference pages. SEOFOMO surveys and market studies are good examples of assets that can earn citations because they carry original data and a stated method.
What good looks like
The site has content assets that are specific, current, useful and credible enough to be cited during discovery and evaluation journeys, and clear enough to earn the click when the user has stronger brand familiarity or commercial intent.
What to avoid
Unsupported claims, outdated stats, thin summaries of other people’s research, anonymous expert content in high-trust topics, and measuring only mentions without linked citation rate.
How to put it into practice
Use my AI traffic vs AI citations research to separate two different optimization goals: earning citations in discovery and evaluation journeys, and earning the click when users already have enough familiarity or intent to visit.
This distinction matters because the pages that get cited are not always the same pages that receive AI traffic. Use the research to identify whether your gap is in the source layer that shapes AI answers, the owned pages that could earn citations, or the pages that should convert AI-assisted demand once users decide to click.
7. Align entity, naming and positioning signals
Are brand, product and category signals consistent across the web?
This is a consistency problem across your owned site and the wider web. AI systems build confidence through repeated, aligned signals. If the brand name, product names, category, audience and description drift across sources, you make yourself harder to identify and recommend.
What to check
- Consistent brand and product naming; aligned company description, category and audience; Organization schema and sameAs that reinforce visible content; accurate founder, author and speaker profiles.
- Check the homepage, About page, product and service pages, LinkedIn, Google Business Profile where relevant, Crunchbase, G2, Capterra, Trustpilot or vertical review platforms, app stores, marketplaces, partner pages and press.
What good looks like
The brand, products, services, audience, category and locations are described consistently across owned pages, structured data, social profiles, review platforms, marketplace listings, partner pages and press mentions.
What to avoid
Updating only your website while stale third-party profiles stay live; using different category descriptions across channels; adding schema that contradicts visible page content.
How to put it into practice
Use the Recognizable and Consistent characteristics in my 10 key characteristics of AI search winning brands guide to check whether your brand is being described consistently across owned and third-party sources.
This is especially useful when AI answers misdescribe your brand, confuse it with another entity, omit key differentiators, or repeat outdated positioning. In those cases, the fix is often not “more content,” but stronger entity clarity and consistency across the site, structured data, profiles, directories, review platforms, partner pages and earned media.
8. Work the third-party source ecosystem
Are we present and accurate in the sources AI systems use?
Understand the source ecosystem behind your target prompts: which sources are cited or clearly influencing the answer even when not visibly cited, whether they mention you accurately, whether they’re current, and whether you can be included, corrected or referenced there. Treat digital PR as part of AI search optimization, not a separate track.
Sources to audit
Industry publications, review platforms, marketplaces, app stores, partner directories, communities such as Reddit, Quora and niche forums where relevant, YouTube and podcasts, analyst and research reports, institutional sites, and local directories and media.
For prompts where third-party sources repeatedly shape the answer, map the source ecosystem before deciding what to do. This helps avoid chasing generic mentions and keeps digital PR, review management and partner updates connected to actual AI search visibility gaps.
| Prompt group | Cited or influencing sources | Source type | Mentions us? | Mentions competitors? | Accuracy | Action |
|---|---|---|---|---|---|---|
| Best X for SMBs | G2, Reddit thread, industry blog | Review / community / publisher | Partial | Yes | Outdated | Update profile, improve review coverage and pitch updated category resource |
| X vs Y | Competitor comparison page, affiliate guide | Owned competitor / affiliate | No | Yes | Mixed | Create or improve comparison page; outreach for correction or inclusion where appropriate |
| Best provider in Spain | Local directory, local publisher, marketplace | Directory / media / marketplace | No | Yes | N/A | Build or update local profiles; earn local proof and citations |
| Is X trustworthy? | Review platform, security page, forum discussion | Review / owned / community | Yes | Yes | Incomplete | Improve trust/security page and correct outdated profile descriptions |
Use this as a working table, not as a static report. The most valuable sources aren’t always the highest-authority domains but the sources that repeatedly appear, get cited or shape answers for the prompts that matter to your audience.
What good looks like
For each priority prompt group, you know which publishers, review sites, marketplaces, communities, directories or institutional sources are cited or influencing answers. You also know whether they mention you, whether the information is accurate, and which action is needed: update, correct, earn inclusion, contribute, monitor or deprioritize.
What to avoid
- Chasing generic mentions without prompt-level source evidence; ignoring sources that repeatedly shape commercial prompts; assuming owned-site work alone fixes third-party gaps.
- Trying to manipulate community sources instead of contributing genuinely useful information. More on this in the closing principle.
How to put it into practice
Use the Corroborated and Credible characteristics in my 10 key characteristics of AI search winning brands guide to prioritize the third-party sources that matter most.
Then use my AI traffic vs AI citations research to connect this work with citation behavior. If AI systems repeatedly cite publishers, review platforms, marketplaces, directories, communities or partner pages for your target prompts, those sources become part of the optimization landscape.
The priority is not to chase generic mentions. It is to identify which sources shape the AI answers you care about, then decide whether the right action is inclusion, correction, updated profiles, reviews, partnerships, expert commentary, original research or digital PR.
9. Make commercial and transactional information machine-readable
Is pricing, product, plan and service information machine-readable?
If pricing, products, plans, availability, locations, integrations or policies aren’t understandable, you lose selection stage prompts by default.
What to make clear by business model
- Ecommerce: names, categories, attributes, price, currency, stock, variants, shipping, returns, reviews, images, offers, merchant information, feed and product structured data.
- SaaS: pricing, plan differences, features, integrations, security and compliance, support, onboarding, use cases, segments, trial or demo, and limitations.
- Services: services offered, ideal-fit clients, markets served, process, deliverables, engagement model where possible, case studies and booking process.
What good looks like
Pricing, plans, product attributes, stock, availability, integrations, policies, locations, service scope and next steps are clear, current and consistent across pages, feeds, structured data and relevant third-party profiles.
What to avoid
Hiding all commercial information behind forms or sales calls; vague pricing; inconsistency across pages, feeds and structured data; leaving key evaluation details only in PDFs, images or sales decks.
How to put it into practice
Use the Transactable characteristic in my 10 key characteristics of AI search winning brands guide to check whether your commercial information is clear enough for AI systems to use in evaluation and selection journeys.
This is where ecommerce, SaaS and service businesses will need different checks. Ecommerce sites should prioritize product pages, feeds, structured data, prices, stock, variants and returns. SaaS sites should prioritize pricing, plans, integrations, security, compliance, onboarding and limitations. Service businesses should clarify who they serve, what they deliver, how the engagement works and what proof supports their positioning.
10. Localize by market, not only by language
Are prompts, sources and trust signals adapted by market?
My study of click-producing AI search traffic across 10 markets using Similarweb data showed how much the click-receiving layer changes by vertical and country. The number of domains needed to capture the first 50% of AI clicks differed by an order of magnitude: a median of about 5 domains in ecommerce, 17 in finance and 47 in travel. In Italian ecommerce, for instance, Amazon.it alone captured about 46.2% of AI ecommerce clicks. AI traffic also frequently went to local infrastructure rather than global defaults.
A US/English playbook doesn’t automatically transfer to other countries: Sources, competitors, marketplaces, review platforms, regulations, terminology and expectations differ.
What to check
Which platforms and prompts matter locally; which competitors and local sources appear; local currencies, units, regulations and terminology; hreflang and indexability of local pages; accuracy of local third-party profiles.
What good looks like
Each priority market has its own prompt sample, competitor set, local source map, terminology, examples, trust signals and commercial details. The local version is not just a translation of the global or US page.
What to avoid
Assuming US/English patterns apply everywhere; one global prompt set; translating pages without adapting sources, terminology and examples; ignoring local competitors that are stronger in AI answers than in classic organic rankings; reporting global AI visibility without market-level segmentation.
How to put it into practice
Use my global AI search strategy guide to adapt the checklist by country, language and source ecosystem.
This step is not only about translating prompts or pages. It is about validating which AI platforms, competitors, publishers, marketplaces, directories, review sources, local regulations, terminology and trust signals influence answers in each market.
For international sites, this also means checking whether local pages, hreflang, structured data, local profiles and third-party sources support the way users actually search, compare and decide in each country.
11. Report without overclaiming
Are observed, proxy and modelled business signals separated and labelled?
AI search measurement is currently a work in progress, and AI traffic might not tell the full impact: A user can discover you in an AI answer, not click, then search your brand directly, visit and convert through another channel. AI referrals undercount AI influence on discovery and evaluation, so don’t position AI traffic as the full value, and as a replacement for traditional organic search yet either.
My April 2026 data is a useful reality check on framing: across the 40 US sites analyzed, organic search was about 20.45% of visits versus roughly 0.19% for AI traffic — organic was around 108x larger.
To assess if AI visibility is translating into value you should use observed, owned proxy, third party proxy and modelled business impact layers to answer different questions:
- Observed: How many users clicked and converted from an AI answer?
- Eg.: AI-referred sessions, conversions, revenue/leads; AI-assisted conversions where referrer/UTM exists; pages with measurable AI referral traffic
- Proxy: own: Is there evidence users are seeing us in AI answers even when they don’t click?
- Eg.: Branded search lift; direct/unattributed lift to pages surfaced in answers; CRM or sales notes and support logs mentioning AI discovery; survey responses
- Proxy: third-party: How does our AI presence compare to competitors and which prompts are driving AI traffic?
- Eg.: Estimated AI traffic share, prompt samples, competitor visibility, cited domains and source overlap
- Modelled: If we assume X% of branded search lift is AI attributable, what is the implied pipeline?
- Eg.: Estimated AI-influenced pipeline/revenue, value of branded demand lift, scenario modelling where direct attribution is unavailable
AI search reporting is useful only if the confidence level is clear. Some signals are observed, some are directional, and some are modelled. They should not be presented as if they carry the same level of certainty.
Avoid reporting these as facts:
- “AI search drove X revenue” when the number is modelled from proxy signals rather than directly observed.
- “We are winning AI search” based on one platform, one prompt set or one test run.
- “Visibility dropped” based on one prompt run without repeated sampling or topic-level analysis.
- “AI traffic is low, so AI search does not matter.” AI can influence discovery and evaluation without producing a directly attributable click.
- “AI search replaced SEO” when organic search remains much larger in most measured traffic datasets.
- “This specific change caused the improvement” without retesting comparable prompt groups and checking whether sources, competitors or platform behavior also changed.
- “Our AI visibility score is up, so performance improved” without checking recommendation rate, linked citation rate, comparative win rate, representation accuracy and business relevance.
A more defensible approach is to label each signal by confidence level, explain the assumptions behind modelled estimates, and keep observed traffic, proxy signals and modelled impact separate.
What good looks like
Observed AI traffic, owned proxy signals, third-party proxy signals and modelled estimates are reported separately. Assumptions are documented, confidence is labelled, and platform-level differences are not hidden inside one blended “AI visibility” number.
What to avoid
Treating AI referral traffic as the full value of AI search; blending observed, proxy and modelled signals into one figure; reporting “AI impact” without confidence labels; comparing platforms without separating them.
How to put it into practice
Use the Business Impact layer in my 3-layer framework to measure AI Presence, Readiness and Business Impact to separate observed results from proxies and modelled estimates.
Then use my AI traffic vs AI citations research to keep the interpretation realistic: citations, mentions, clicks and later conversions can happen at different points in the journey. AI referral traffic is useful, but it is not the full value of AI search visibility. Modelled AI-influenced revenue can be helpful, but it should never be presented as directly observed revenue.
12. Run a recurring validation and optimization loop
Are we monitoring change and turning gaps into actions?
Re-run priority prompts, compare against the previous period, identify new or lost mentions, check whether recommendations and linked citations changed, validate representation accuracy, track new cited sources and competitor movement, map changes to likely causes, and update the roadmap. Then confirm whether visibility actually moved after each change, don’t update pages and assume.
Prioritization I use
Visibility gap severity x business importance x likelihood of influence / implementation effort. Prioritize with effort along with impact.
Validation after implementation
After implementing changes, validate whether the expected visibility signal actually moved. Do not update pages, profiles or structured data and assume the issue is fixed.
| Change implemented | What to validate |
|---|---|
| Updated comparison page | Comparative win rate, recommendation rate, cited sources, representation accuracy and competitor framing. |
| Added pricing, plan or product details | Commercial prompt visibility, linked citation rate, accuracy of price/plan descriptions and evaluation-stage answers. |
| Improved page structure and extractability | Linked citation rate, section-level surfacing, quality of summaries and whether the owned page is cited more often. |
| Fixed schema, entity information or profile consistency | Representation accuracy, entity confusion, brand/category descriptions and sameAs/profile alignment. |
| Updated third-party profile or marketplace listing | Accuracy in AI answers, whether the source is cited, and whether outdated descriptions persist. |
| Earned new mention, review or inclusion in a cited source | Prompt coverage, cited-source overlap, competitor comparison and recommendation language. |
| Added original research, survey or benchmark | Citation rate, third-party references, linked citations and whether the asset appears in discovery/evaluation answers. |
| Localized a market page or profile | Local prompt coverage, local competitors, local sources, language/terminology accuracy and local linked citations. |
| Improved product feed or commercial data consistency | Accuracy of price, stock, availability, variants, product attributes and transactional answers. |
| Changed crawler access or rendering setup | Crawler access, indexing, raw vs rendered HTML, log-file evidence and whether priority pages become retrievable. |
How often should you run this checklist?
AI search optimization should be treated as a recurring workflow, not a one-off audit. The right cadence depends on the size of the site, the speed of the category, the importance of AI search to the business and how often products, prices, competitors and sources change.
| Cadence | What to review |
|---|---|
| Monthly | Priority commercial prompts, branded prompts, major competitors, linked citation patterns, representation accuracy and top AI-referred pages. |
| Quarterly | Prompt library expansion, source ecosystem review, comparison pages, third-party profiles, review platforms, local-market checks and commercial data consistency. |
| After major changes | Product launches, pricing changes, rebrands, new markets, major PR campaigns, site migrations, template changes, core updates or significant AI platform changes. |
| Annually | Full AI search readiness review, business impact review, international source ecosystem review and prioritization refresh. |
The important part is to keep the same prompt groups and documentation structure long enough to see patterns. If the prompt set, markets, platform mix and criteria change every time, the reporting becomes much harder to interpret.
What good looks like
The same prompt groups are re-tested over time, changes are documented, sources are monitored, competitor movement is reviewed, and the roadmap is updated based on what changed, what didn’t and what still needs diagnosis.
What to avoid
Treating this as a one-off; re-running prompts without documenting changes; focusing only on visibility and ignoring accuracy; reporting metrics without turning them into actions.
How to put it into practice
Use the 3-layer framework to measure AI Presence, Readiness and Business Impact to keep the validation process structured, and revisit the 10 key characteristics of AI search winning brands when performance changes.
The loop shouldn’t only ask whether visibility improved. It should also check whether the brand is more accurately represented, whether the right sources are being cited, whether recommendations changed, whether competitors moved, and whether the implemented fixes had the expected effect.
For international sites, revisit the global AI search strategy guide periodically too, since local source ecosystems, competitors and click-receiving patterns can change by market and vertical.
The minimum viable AI search optimization workflow
If you don’t have time to run the full checklist immediately, start with a minimum viable workflow. This gives you enough signal to avoid random optimization and to prioritize the work most likely to affect visibility, citations, recommendations and representation accuracy.
- Select 30–50 commercially relevant prompts, grouped by product, service, market, persona or journey stage.
- Run them across the two or three AI search platforms most relevant to your audience.
- Record whether your brand appears, is recommended, is linked, is cited and is described accurately.
- Capture the sources cited or clearly shaping the answer.
- Identify which competitors appear, where they are preferred, and why.
- Map each gap to one of three broad fix types: owned page/content issue, third-party source ecosystem issue, or data/entity/commercial clarity issue.
- Prioritize fixes by business importance, visibility gap severity, likelihood of influence and implementation effort.
- Re-test the same prompt groups after changes, and compare the results at topic level rather than reacting to one prompt run.
This doesn’t replace a broader readiness or measurement framework, but it gives teams a practical starting point that connects measurement to action.
The AI Search Optimization Checklist at a Glance
| # | Checklist area | Key question |
|---|---|---|
| 1 | Prompt and journey definition | Are we optimizing for the prompts and journeys that actually matter? |
| 2 | Current AI presence | Do we appear, get recommended, get cited and get described accurately? |
| 3 | Gap diagnosis | Which readiness characteristic is actually causing the gap? |
| 4 | Retrievable and extractable | Can systems reach, render and isolate our priority pages? |
| 5 | Decision-support content | Do our pages help users compare, evaluate and choose? |
| 6 | Citation and click | Are we trusted enough to be cited and useful enough to be linked? |
| 7 | Entity and positioning | Are brand, product and category signals consistent across the web? |
| 8 | Third-party sources | Are we present and accurate in the sources AI systems use? |
| 9 | Commercial clarity | Is pricing, product, plan and service information machine-readable? |
| 10 | International and local | Are prompts, sources and trust signals adapted by market? |
| 11 | Reporting | Are observed, proxy and modelled signals separated and labelled? |
| 12 | Recurring validation | Are we monitoring change and turning gaps into actions? |
Final takeaway
AI search optimization should not start with “let’s make more AI-friendly content.”
It should start with: which AI search journeys do we want to influence, where are we visible or missing, which sources shape the answers, and what do we need to improve to be selected, cited, recommended and accurately represented?
That is the difference between generic AI content optimization and a defensible AI search process and it is why this checklist runs on top of the readiness characteristics and the metric layers rather than alongside them.
One principle that keeps this defensible: Don’t optimize by exploiting AI systems’ current weaknesses.
Prompt injection, fabricated reviews, manufactured community signals and citation gaming can produce a short-term bump, but they target blind spots that get patched, and they trade durable trust for fragile visibility.
The goal is to make your brand, content, data, proof and source ecosystem clear enough, useful enough, credible enough and accessible enough to be included, trusted and chosen in the AI-assisted journeys that matter to your business. That is the visibility that lasts.
Complementary AI search guides
- The 10 Key Characteristics of AI Search Winning Brands
- A 3-Layer Framework to Measure AI Presence, Readiness and Business Impact
- AI Traffic vs AI Citations: What Clicks and Cited Pages Show About the AI Search Journey
- Where AI Search Sends Traffic: 10-Market Patterns for Your Global AI Search Strategy



